
Concepts
Even if you have little or no experience with Git, we made it very easy to use Git from inside Hackolade Studio, without compromise on the power of Git in more advanced situations. You just need to become familiar with the concepts below.
Note: as with any new technology, concepts may be different than what you've been used to with other vendors. Maybe you are used to doing "checkout" of a data model and lock it so other users cannot make any changes until you "checkin" that model. Git works differently, so you may need to adjust your habits. But you'll quickly realize that it is much more flexible, letting different users make changes simultaneously, then reconciling them at a later stage, most often without manual intervention.
Warning: some terms used in a Git context may have a different meaning than in other technologies, e.g. checkout.
Remote repository
The term "remote repository" may be intimidating, but it simply means the "central storage", in this case for your data models. It is "remote", in the sense that it is not "local". And it differs from a traditional folder in the sense that it is enabled for tracking changes in text files. As a result, every time someone "saves" a file into a remote repo, an immutable state and history is automatically logged and accumulated. Immutability does not mean that you cannot make additional changes. It simply means that you cannot rewrite history: you may only make additional changes (possibly if necessary, to undo some other change made in the past) in a new version of that file. It is easy to see when a change was made and by whom.
Note that an additional benefit of Git is that it is not necessary to explicitly create new versions of a file: each new commit made on the remote repo is a new and automatic version of the file. It is possible to capture a milestone in the Git history, generally to mark a version release (i.e. v1.0.1), by creating a tag, which is a marker pointing to a specific state of the repository, an arbitrary commit.
Remote vs Local repo
One of the many advantages of Git vs previous source control systems, is that it can be (and often is) "distributed", as opposed to strictly central. In the old days, collaborating on a central file imposed a big constraint on collaboration. In most cases, it was necessary for one user to "checkout" the file and lock it so no one could make changes in parallel. Then when finished, the user would do a "checkin" of the new version into the central storage. When using the distributed nature of Git, users are able to make changes in parallel on the same file, being confident that these changes will be automatically merged. If a conflict occurs, there is a method for a user to easily resolve these conflicts.
There are 2 ways to work with a remote repository:
- for occasional access, or users simply consulting models in read-only mode, they may access the central storage directly. It is possible to operate in read-write mode to create a new or modify an existing file (and Hackolade Studio supports this mode since v8.1.2), but users lose several benefits, as described below.
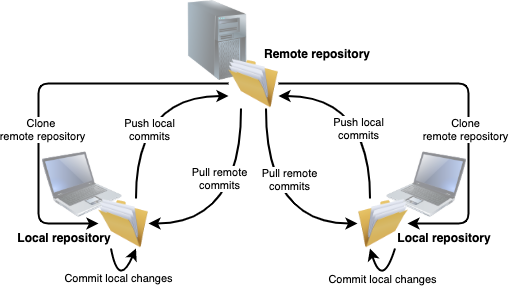
- for more intensive use with a richer experience and feature set, by cloning the remote repository on the user's local machine. The richer experience includes the benefits related to the distributed nature of Git: advanced features, ability to group changes to multiple files in sets, more flexible collaboration, offline access, multiple backups, etc.
Clone
Cloning a repository is the action of creating a copy of that repository. The most typical use case is for a user to clone a "remote" repository into a "local" folder.
Note that every clone of a repository contains the full content and history of that repository. This makes it possible for you to explore and work in your local repository while being offline. You only need a network connection when you decide to upload your changes to the remote repository, or to download the changes made by other users.
You can clone as many repositories as you want. You can open each of them individually in Hackolade Studio. If you start multiple instances of Hackolade Studio, each instance can have a different repository open, or the same one.
Cloning a remote repository should normally happen only once, whereas the other actions below typically happen on a regular basis.
Note: we skipped on purpose the concept of creating a repository. In most cases, you will work with existing repositories, created by the administrator in your organization. If you need to create a new repo, you should create it first on your provider's platform (GitHub, GitLab, Bitbucket, Azure Repos), then clone it in Hackolade Studio as described here.
Commit
Once you have your local clone of a repository, you can start making changes in the files that it contains, mainly Hackolade data models in our case. You may also create new data models and save them into your local repository folder and sub-folders.
When you save your changes to a data model, they are, as usual, written to your file system. However, at this stage, they are not tracked by Git yet. You need one extra step to add your changes to the Git history: you need to commit them. Once you have committed your changes, they appear as an atomic modification in the history of your local repository.
The changes that you commit are not immediately available to other users in your team. The next step is to push your commits to the remote repository.
Note that a commit can contain multiple changes, possibly in multiple files. It is a good practice to include, in a single commit, file changes that relate to one another, and to give every commit a meaningful description.
It is important to note that a commit, once it has been pushed to the remote repo, is a fairly immutable piece of Git history. For integrity reasons, Hackolade Studio does not let users erase or cancel a commit from the Git history. It can only be discarded undone via a revert operation. If more specific actions are required, only experts should rewrite history, and perform these actions outside of Hackolade Studio.
Prior to being pushed, a commit can be discarded, or stashed.
Pull
Pulling remote commits is the action of downloading from the remote repository the commits that have been pushed by other users. As long as you don't pull these commits, those changes are not available to you.
Push
Pushing your local commits is the action of publishing them to the remote repository to make them available to other users. As long as you don't push your local commits, changes are only available to you.
Note that you need to commit your changes prior to pushing them. Uncommitted changes will not be pushed. Also, you may make several local commits before pushing them to the remote repository (e.g. after working in offline mode for a while.)
Conflict
Conflicts can happen when pulling remote commits, in case you modified a line in a file that has also been modified differently by someone else. Hackolade Studio assists you in solving conflicts in data model files through an interactive merge dialog.
Chances for conflicts are minimized by the structure of Hackolade data model files, whereby each property, of each attribute, of each entity, of each container is its own line in a data model file.
Best practice: to reduce the risks of facing conflicts, we recommend that you regularly pull remote commits. This will ensure that your local repository is up-to-date with all the changes that have been recently pushed by other team members to the remote repository. If you are about to start modifying a data model, then you should definitely pull first from the remote repository.
It is also a good idea to regularly push your commits to the remote so other team members are aware of your changes.
Branch
Git does more than tracking a linear sequence of commits. It supports branching to create independent sequences of commits that belong together. Such a sequence is called a branch.
A branch can be short-lived, to track small fixes for example. A branch could also be open for awhile, for example when developing the features of a new major version.
The picture below is an example of what the history of a repository can look like. Every circle represents one commit. There are sometimes multiple distinct sequences of commits (branches) running in parallel.

When you open a repository, what you see is the content of the repository on the branch that is currently active (there is always at least one branch in a repository).
When you commit your changes, you commit them on the active branch.
You can create as many branches as you need. You can switch from one branch to another. In Git terms, these actions are both called "checkout". This term is not to be confused with the concept of checkout in other technologies. The term checkout in a Git context means selecting a branch, whether the branch is an existing one or a new one.
When you checkout a branch, it becomes the active branch. Every change you make only affects that branch. Other branches remain untouched.
When you checkout a new branch, it is only available to you in your local repository. It becomes available for other people only after you push the commits that you made on that branch to the remote repository.
You can merge a branch into another one.
You can delete a branch (after merging it, or not merging it.)
Note: you should should choose carefully the basis for your new branch, if that basis is any other branch than main/master. This is because a new branch inherits all the history and content of the branch on which it is based. This article explains Git branches with a LEGO analogy.
Create a change/merge/pull requests
The peer review feature is a very popular collaboration extension to Git, supported by most of the repository hubs. It allows changes made by a user to be submitted for review and approval by another user before being merged into a target branch.
Changes to data models are proposed in a branch, to ensure that the target branch only contains finished and approved work. Anyone with read access to a repository is allowed to submit changes for review.
Note: the naming conventions differ slightly between repository hub providers. GitHub, for example, uses the terminology pull requests, whereas GitLab uses merge requests. Both refer to the same concept. Hackolade Studio takes into account the specific terminology of the hub provider. However, in this documentation, we abstract them and refer to the more generic "change requests".
Review of change/merge/pull requests
Peers may comment a change request and solicit adjustments to be made to the data models in the branch. Designated reviewers may approve or reject change requests.
Tags
A Git tag is a reference pointing to a specific commit in the Git history. Tagging is used to capture a milestone in the Git history, generally to mark a version release (i.e. v1.0.1). The Git client makes it possible to tag a given commit with an arbitrary name. It is also possible - but not mandatory - to provide a description when tagging a commit.