
SQL Server
SQL Server is a relational database management system developed by Microsoft, aimed at different audiences and for workloads ranging from small single-machine applications to large Internet-facing applications with many concurrent users.. There is also a cloud-based version, Azure SQL database, presented as a platform-as-a-service offering on Microsoft Azure.
JSON functions in SQL Server enable users to combine NoSQL and relational concepts in the same database. Users can combine classic relational columns with columns that contain documents formatted as JSON text in the same table, parse and import JSON documents in relational structures, or format relational data to JSON text.
To perform data modeling for SQL Server and Azure SQL Database with Hackolade, you must first download the SQL Server plugin.
Hackolade was specially adapted to support the data modeling of SQL Server and Azure SQL Database, including schemas, tables and views, indexes and constraints, plus the generation of DDL Create Table syntax.
In particular, Hackolade has the unique ability to model complex semi-structured objects stored in columns of the (N)VARCHAR(MAX) and (N)VARCHAR(4000) data types. We're not talking about functions that "flatten" JSON into standard columns, which runs the risk of inconsistencies, if not errors, when doing the Cartesian product of multiple complex data types. But about the storage of entire JSON documents. The reverse-engineering function, if it detects JSON documents, will sample records and infer the schema to supplement the DDL table definitions.
The data model in the picture below results from the data modeling of the AdventureWorks sample database:
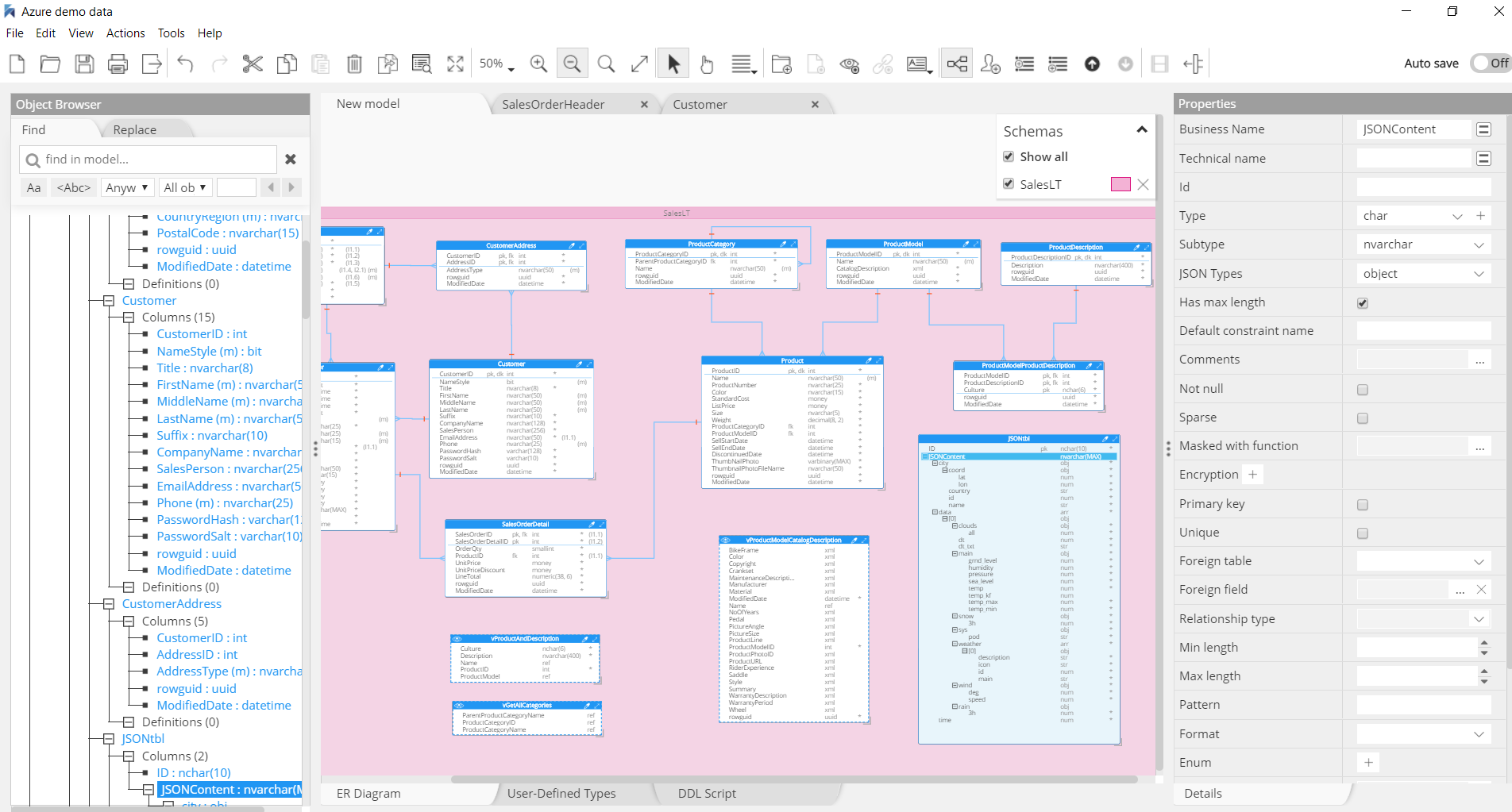
Schemas
SQL Server tables are contained within database object containers that are called schemas. The schema also works as a security boundary, where you can limit database user permissions to be on a specific schema level only.
Tables
All data in SQL Server is stored in database tables, logically structured as collections of columns and rows, optionally with single-column or multi-column constraints.
Unique, Primary, and Foreign Keys, plus Not Null, Check and Default constraints
Constraints in SQL Server are predefined rules and restrictions that are enforced in a single column or multiple columns, regarding the values allowed in the columns, to maintain the integrity, accuracy, and reliability of that column’s data. Constraints in SQL Server can be defined at the column level, where it is specified as part of the column definition and will be applied to that column only, or declared independently at the table level.
There are six main constraints that are commonly used in SQL Server: NOT NULL, UNIQUE, PRIMARY, FOREIGN, CHECK, and DEFAULT.
Indexes
The goal of an index on a database table then is to reduce I/O. Properly indexing a SQL Server table is key to providing consistent, optimal performance. There are many things to consider when designing an index structure, but this goes beyond the scope of this document.
Hackolade supports the most common types of SQL Server indexes, but not all of them yet. Currently, the following types of indexes are not supported: hash, memory-optimized nonclustered, filtered, spatial, XML, and full-text.
Data types
In SQL Server, each column, local variable, expression, and parameter has a related data type. A data type is an attribute that specifies the type of data that the object can hold: integer data, character data, monetary data, date and time data, binary strings, and so on.
Additionally, in (N)VARCHAR(MAX) and (N)VARCHAR(4000) columns, Hackolade supports the data modeling of JSON files with standard JSON data types: string, number, object, array, boolean, and null.
User-defined data types are based on the data types in SQL Server. User-defined data types can be used when several tables store the same domain of values in a column and must ensure that these columns have exactly the same data type, length, and NULLability.
Views
A view is a virtual table whose contents are defined by a query. Like a table, a view consists of a set of named columns and rows of data. Unless indexed, a view does not exist as a stored set of data values in a database. The rows and columns of data come from tables referenced in the query defining the view and are produced dynamically when the view is referenced. A view acts as a filter on the underlying tables referenced in the view. The query that defines the view can be from one or more tables or from other views in the current or other databases.
Forward-Engineering
Hackolade dynamically generates the DDL script to create schemas, tables, columns and their data types, indexes and constraints for the structure created with the application.
The script can also be exported to the file system via the menu Tools > Forward-Engineering, or via the Command-Line Interface.
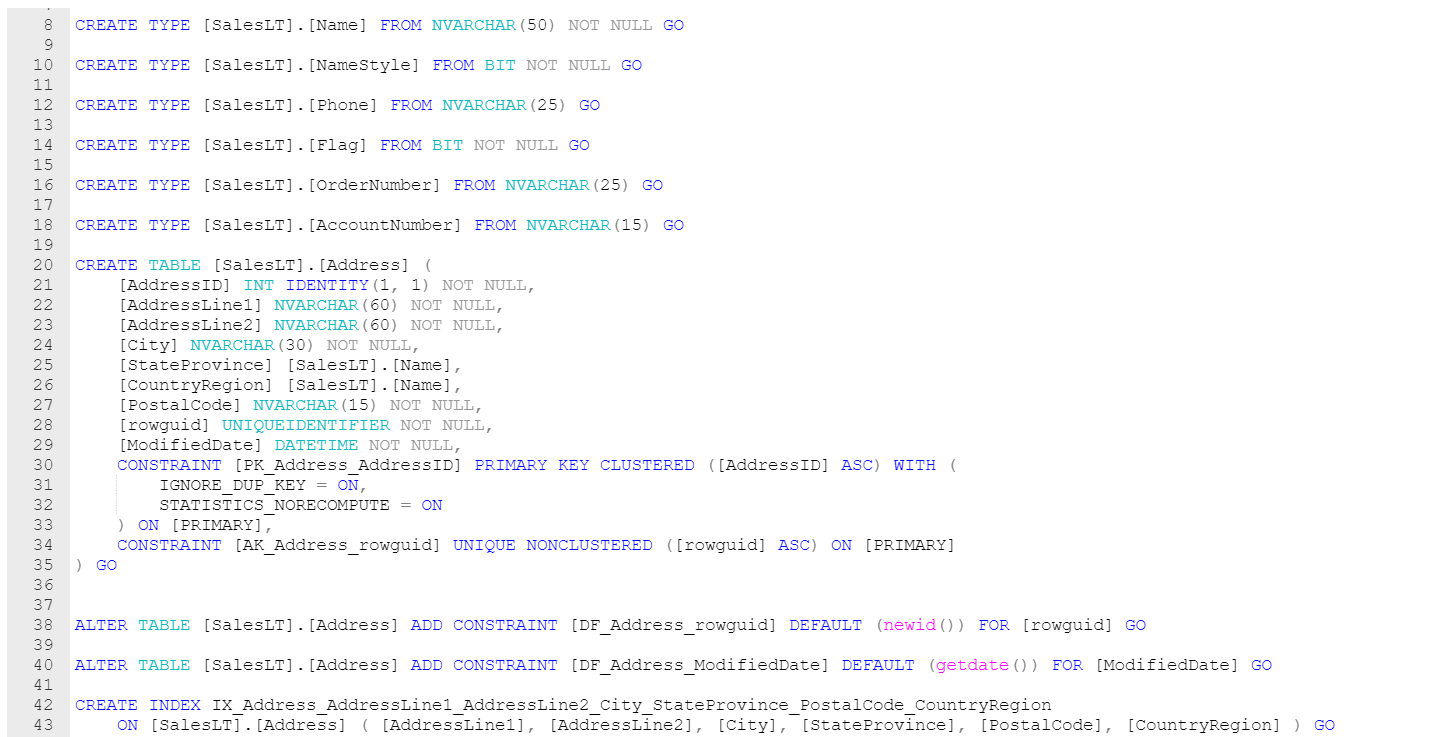
If you store JSON within (N)VARCHAR(MAX) or (N)VARCHAR(4000) columns, Hackolade allows for the schema design of those documents. However, the corresponding JSON structure is not forward-engineered in the DDL script, but is useful for developers, analysts and designers.
Reverse-Engineering
The SQL Server engine can hosted on-premises, on virtualized machines in a private or public cloud, or as a managed instance with the Azure SQL Database service. Details on how to connect Hackolade to SQL Server can be found on this page.
The Hackolade process for reverse-engineering of SQL Server databases includes the execution of statements to discover schemas, tables, columns and their types, indexes and constraints. If JSON is detected in (N)VARCHAR columns, Hackolade performs statistical sampling of records followed by probabilistic inference of the JSON document schema.
For more information on SQL Server in general, please consult the website and documentation.