
JanusGraph
JanusGraph is an open-source, distributed, massively scalable graph database, optimized for storing and querying graphs containing hundreds of billions of vertices and edges distributed across a multi-machine cluster. JanusGraph provides native support for the property graph data models exposed by Apache TinkerPop, as well native support for the graph traversal language Gremlin.
JanusGraph is focused on compact graph serialization, rich graph data modeling, and efficient query execution. It implements robust, modular interfaces for data persistence, data indexing, and client access. JanusGraph’s modular architecture allows it to interoperate with a wide range of storage, index, and client technologies.
Each JanusGraph graph has a schema comprised of the edge labels, property keys, and vertex labels. It is strongly encouraged to explicitly define all schema elements and to disable automatic schema creation by setting schema.default=none in the JanusGraph graph configuration. An explicitly defined schema is an important component of a robust graph application and greatly improves collaborative software development. Note, that a JanusGraph schema can be evolved over time without any interruption of normal database operations. Extending the schema does not slow down query answering and does not require database downtime.
To perform data modeling for JanusGraph with Hackolade, you must first download the JanusGraph plugin. You can find more details on graph-specific controls in this page.
Hackolade was specially adapted to support the data modeling of vertex labels and edge labels and their respective properties. The application closely follows the terminology of the database. To be clear, Hackolade is not a graph visualization tool, but a tool for data modeling of JanusGraph graph databases.
The data model in the picture below results from the reverse-engineering of a sample graph imported in JanusGraph. Two views of the data model are available:
1) a graph view, with familiar circular vertex labels:

2) an Entity-Relationship Diagram (ERD) view, with the advantage of displaying properties for both vertex labels and edge labels:
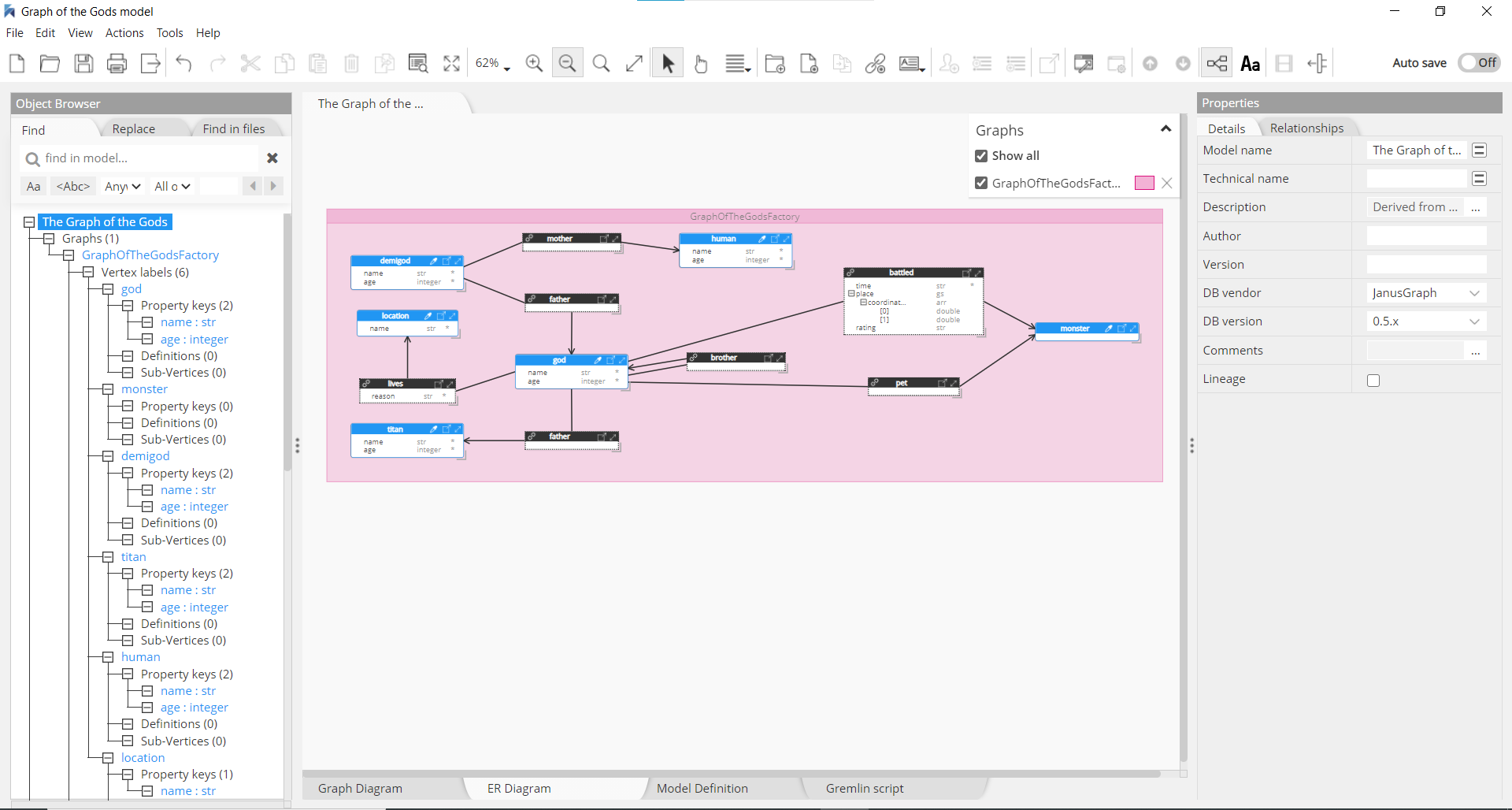
Vertex labels
Vertex labels are a semantic representation of vertices in the graph. Vertex labels are used to represent the role of the vertex in the domain, making it possible to query the graph, to define constraints, and add indexes for properties. Labels can also be used to mark temporary states of a vertex.
Vertex labels can be defined as static which means that vertices with that label cannot be modified outside the transaction in which they were created.
Vertex labels can be configured with a time-to-live (TTL). Vertices with such labels will automatically be removed from the graph when the configured TTL has passed after their initial creation. TTL configuration is useful when loading a large amount of data into the graph that is only of temporary use. Defining a TTL removes the need for manual clean up and handles the removal very efficiently.
Vertex TTL is defined on a per-vertex label basis, meaning that all vertices of that label have the same time-to-live. The configured TTL applies to the vertex, its properties, and all incident edges to ensure that the entire vertex is removed from the graph. For this reason, a vertex label must be defined as static before a TTL can be set to rule out any modifications that would invalidate the vertex TTL. Vertex TTL only applies to static vertex labels.
Property keys
A vertex label usually has attributes, called "property keys" where the name (or key) is a string.
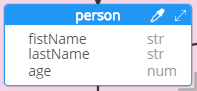
JanusGraph supports multiple properties with the same key on a single vertex.
Property key data types
JanusGraph will enforce that all values associated with the key have the configured data type and thereby ensures that data added to the graph is valid.
JanusGraph natively supports the following data types:

Complex data types can also be defined:
- Map
- List
- Set
- Array
- GeoShape
It is possible to define the allowed cardinality of the values associated with the key on any given vertex.
- SINGLE: Allows at most one value per element for such key. In other words, the key-value mapping is unique for all elements in the graph. The property key birthDate is an example with SINGLE cardinality since each person has exactly one birth date.
- LIST: Allows an arbitrary number of values per element for such key. In other words, the key is associated with a list of values allowing duplicate values. Assuming we model sensors as vertices in a graph, the property key sensorReading is an example with LIST cardinality to allow lots of (potentially duplicate) sensor readings to be recorded.
- SET: Allows multiple values but no duplicate values per element for such key. In other words, the key is associated with a set of values. The property key name has SET cardinality if we want to capture all names of an individual (including nick name, maiden name, etc).
The default cardinality setting is SINGLE.
Edge labels
Each edge connecting two vertices has a label which defines the semantics of the relationship. Edge labels are a semantic representation of relationships in the graph. Every relationship must have one and only type, and 2 nodes can be linked by several relationship types. Relationship types are used during complex traversals across the graph, when only certain kinds of paths from node to node are necessary for a specific query.
In JanusGraph, edges are bi-directional by default. If you set edge labels to be unidirectional, they can only be traversed in the out-going direction.

As JanusGraph is a type of graph database known as 'property graph', edge labels may have attributes, called property keys, just like vertex labels:

The multiplicity of an edge label defines a multiplicity constraint on all edges of this label, that is, a maximum number of edges between pairs of vertices. JanusGraph recognizes the following multiplicity settings:
- MULTI: Allows multiple edges of the same label between any pair of vertices. In other words, the graph is a multi graph with respect to such edge label. There is no constraint on edge multiplicity.
- SIMPLE: Allows at most one edge of such label between any pair of vertices. In other words, the graph is a simple graph with respect to the label. Ensures that edges are unique for a given label and pairs of vertices.
- MANY2ONE: Allows at most one outgoing edge of such label on any vertex in the graph but places no constraint on incoming edges. The edge label mother is an example with MANY2ONE multiplicity since each person has at most one mother but mothers can have multiple children.
- ONE2MANY: Allows at most one incoming edge of such label on any vertex in the graph but places no constraint on outgoing edges. The edge label winnerOf is an example with ONE2MANY multiplicity since each contest is won by at most one person but a person can win multiple contests.
- ONE2ONE: Allows at most one incoming and one outgoing edge of such label on any vertex in the graph. The edge label marriedTo is an example with ONE2ONE multiplicity since a person is married to exactly one other person.
The default multiplicity is MULTI.
Indexes
JanusGraph supports two different kinds of indexing to speed up query processing: graph indexes and vertex-centric indexes. Most graph queries start the traversal from a list of vertices or edges that are identified by their properties. Graph indexes make these global retrieval operations efficient on large graphs. Vertex-centric indexes speed up the actual traversal through the graph, in particular when traversing through vertices with many incident edges.
Graph indexes
Graph indexes are global index structures over the entire graph which allow efficient retrieval of vertices or edges by their properties for sufficiently selective conditions.
JanusGraph distinguishes between two types of graph indexes: composite and mixed indexes.
Composite indexes are very fast and efficient but limited to equality lookups for a particular, previously-defined combination of property keys. Mixed indexes can be used for lookups on any combination of indexed keys and support multiple condition predicates in addition to equality depending on the backing index store.
-
Use a composite index for exact match index retrievals. Composite indexes do not require configuring or operating an external index system and are often significantly faster than mixed indexes.
- As an exception, use a mixed index for exact matches when the number of distinct values for query constraint is relatively small or if one value is expected to be associated with many elements in the graph (i.e. in case of low selectivity).
-
Use a mixed index for numeric range, full-text or geo-spatial indexing. Also, using a mixed index can speed up the order().by() queries.
Vertex-centric indexes
Vertex-centric indexes can speed up such traversals by using localized index structures to retrieve only those edges that need to be traversed.
Vertex-centric indexes can be built in both direction which means that edges can be served by this index in both the IN and OUT direction. Alternatively, one could define the index to apply to the OUT direction only which would speed up traversals in one direction, but not the other.
Multiple vertex-centric indexes can be built for the same edge label in order to support different constraint traversals.
Forward-Engineering
An explicitly defined schema is an important component of a robust graph application and greatly improves collaborative software development. And a JanusGraph schema can be evolved over time without any interruption of normal database operations. The schema designed with Hackolade can easily be applied to a JanusGraph instance, along with a sample graph, using auto-generated Gremlin syntax. The script also includes the creation of indexes.
The script can also be exported to the file system via the menu Tools > Forward-Engineering, or via the Command-Line Interface.
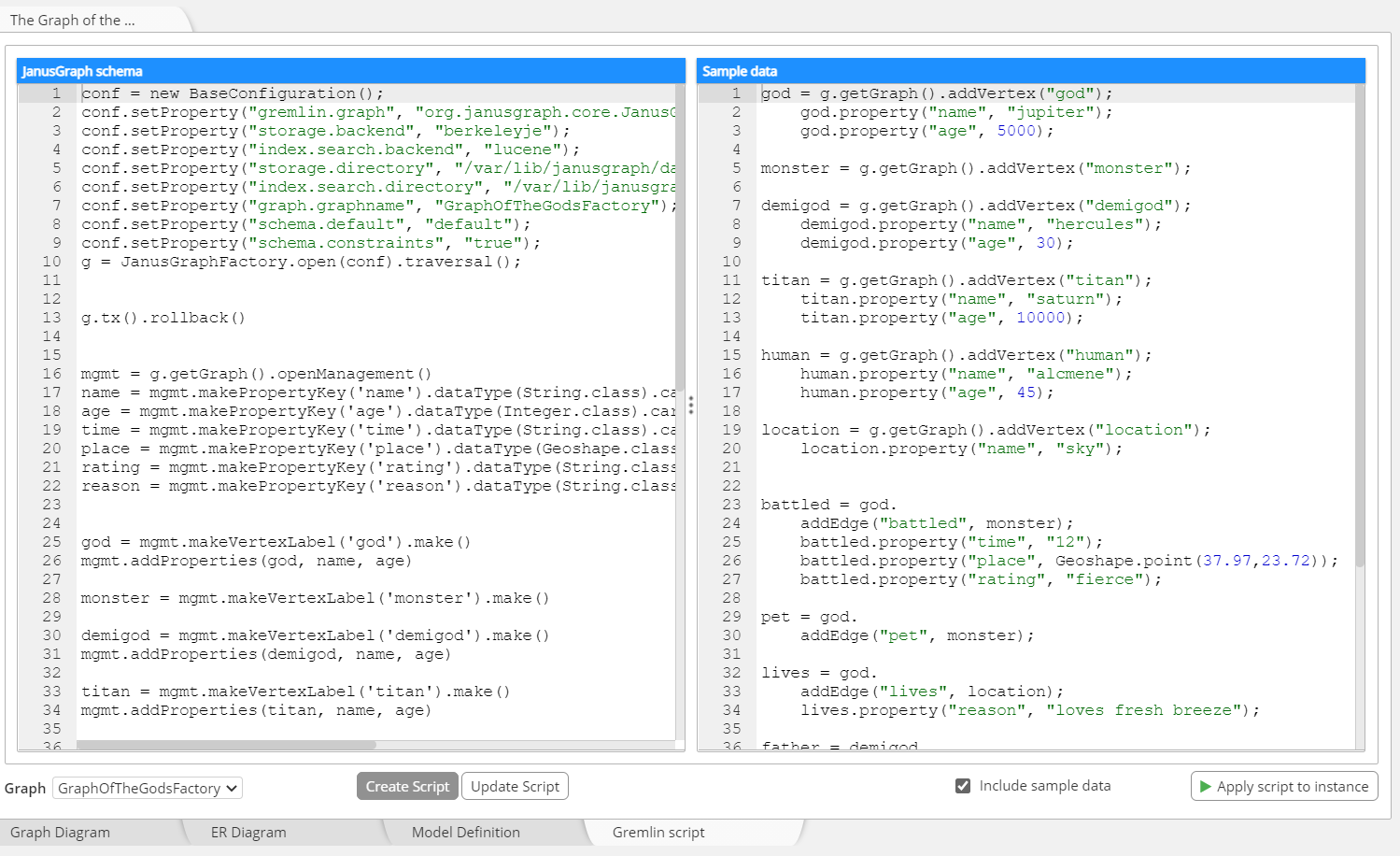
Reverse-Engineering
The connection to a JanusGraph instance is established using a connection string including URI address and port (typically 8182), and authentication using username and password. Hackolade also supports SSL and SSH. Details on how to connect Hackolade to a JanusGraph instance can be found on this page.
For more information on JanusGraph in general, please consult the website.and documentation.