
Overview of JSON and JSON Schema
You may also view this tutorial on YouTube. Summary slides can be found here.
JSON
JSON stands for JavaScript Object Notation. It is a lightweight data-interchange format. It is easy for humans to read and write. It is easy for machines to parse and generate.
According to json.org, JSON is built on two structures:
- A collection of name/value pairs. In various languages, this is realized as an object, record, struct, dictionary, hash table, keyed list, or associative array.
- An ordered list of values. In most languages, this is realized as an array, vector, list, or sequence.
An object is an unordered set of name/value pairs. An object begins with a { left brace and end with a } right brace. Each name is followed by a : colon and the name/value pairs are separated by a , comma.
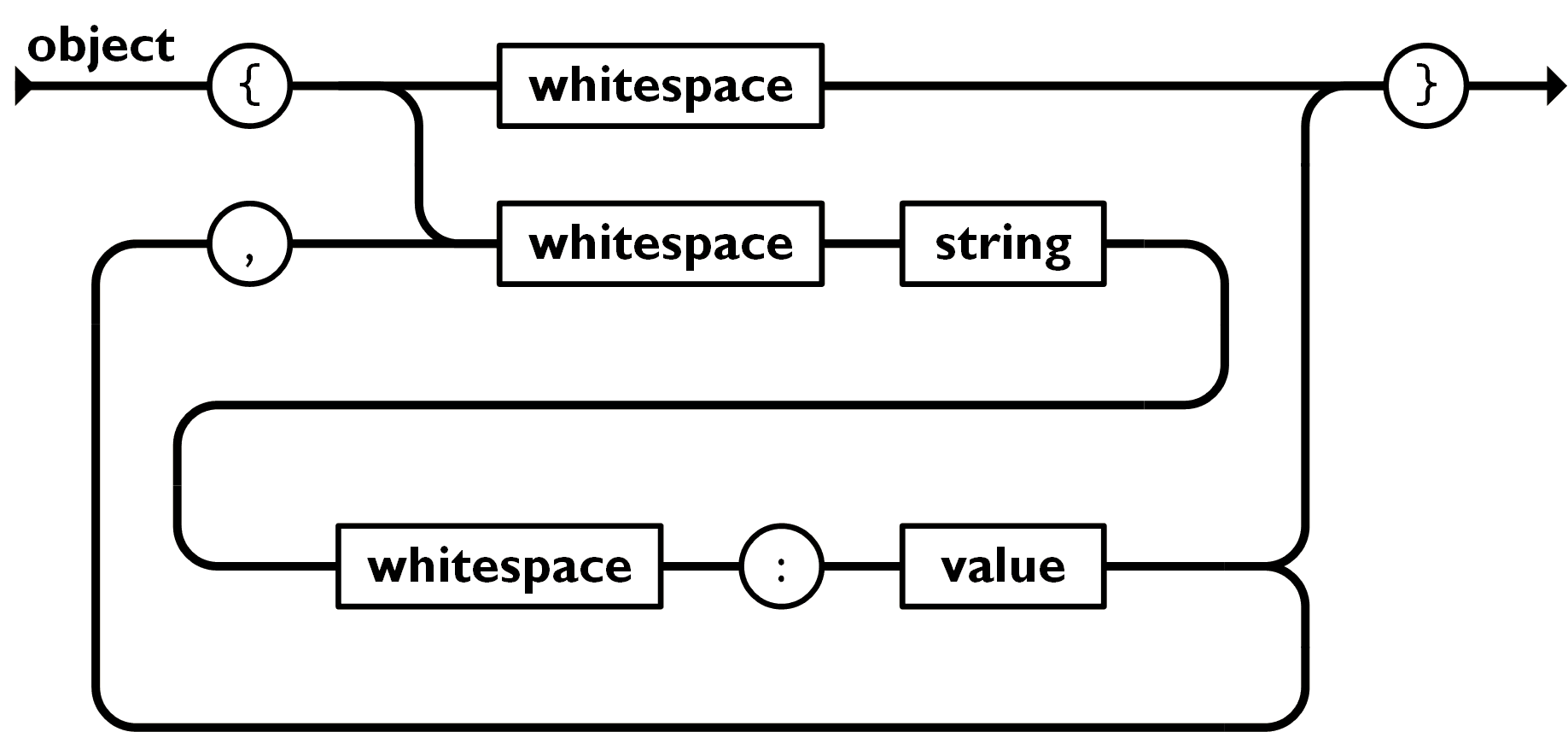
An array is an ordered collection of values. An array begins with a [ left bracket and end with a ] right bracket. Values are separate by a ,comma.
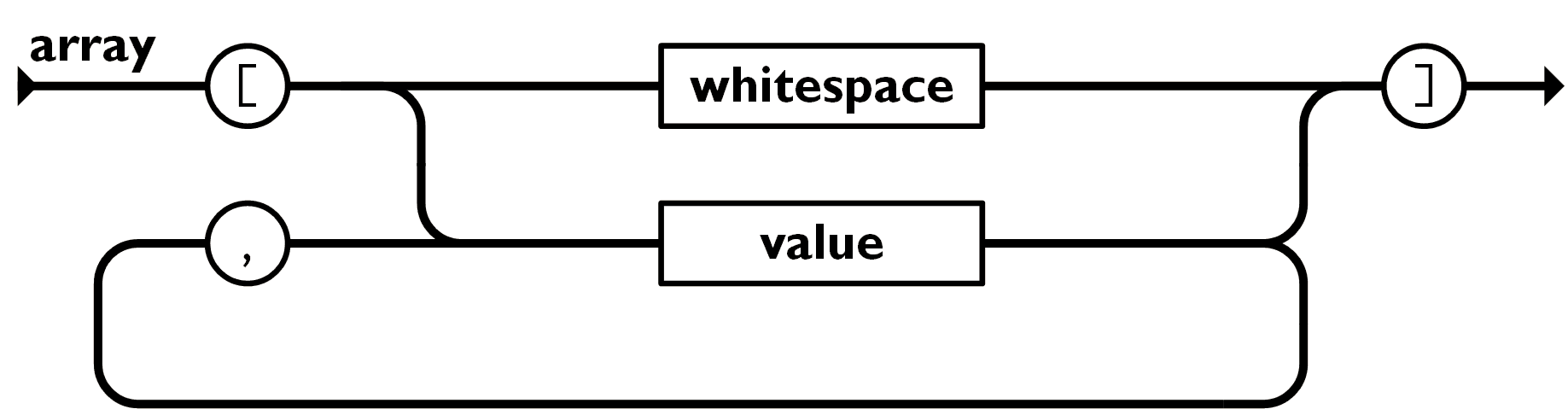
A value can be a string in double quotes, or a number, or true or false or null, or an object or an array. These structures can be nested.
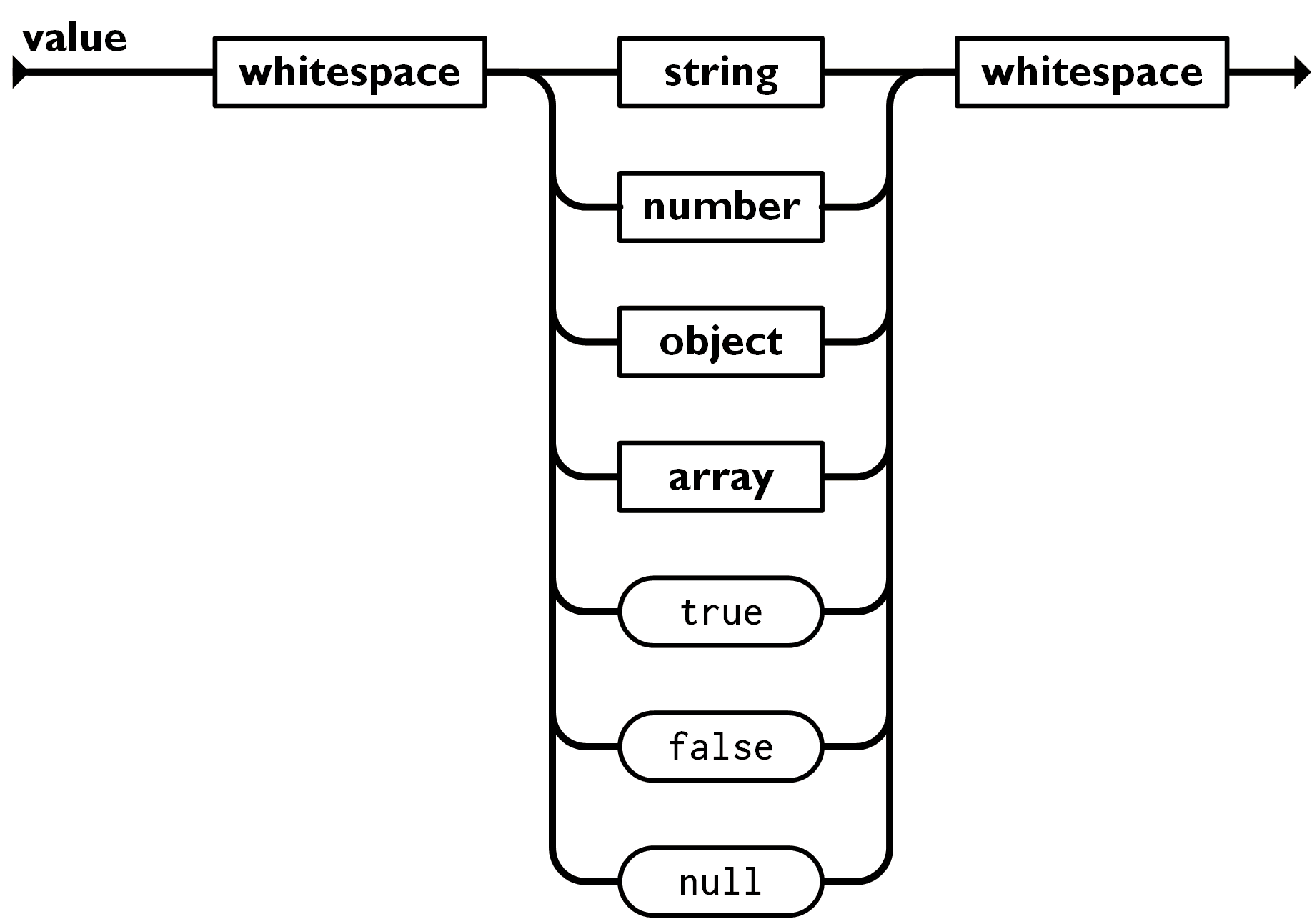
Keys must be strings (text) and values must be valid JSON data types: string, number, another JSON object, array, boolean or null.
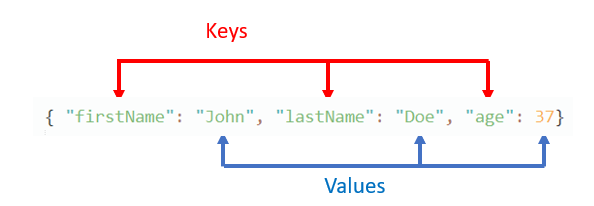
There are infinite ways to organize JSON objects, depending on your needs. It can be as simple as a list or attributes (keys) and values, or it can become very complex with nested JSON objects, arrays of JSON objects, arrays inside attributes, etc...
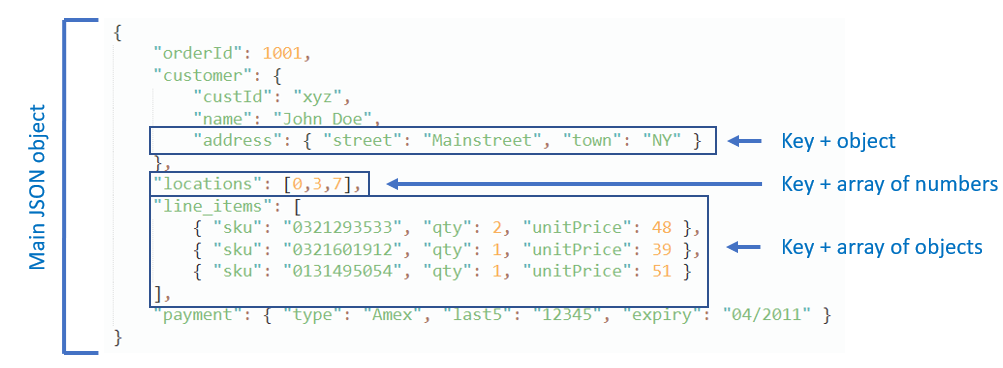
JSON in databases
One of the big advantages of document databases such as MongoDB, Couchbase, DocumentDB, Elasticsearch, etc., besides their distributed horizontal scalability, is that you can leverage the flexibility and easy evolution of JSON documents.
- you can embed information using objects, arrays or a combination thereof to capture relationships between data into a single document structure, thereby denormalizing the data and avoiding expensive joins while maintaining integrity of the transactions
- collections of documents do not require that all the documents have the same schema: some may have more fields than others, plus the data type of some fields may differ across documents of the same collection. Be careful however about this point... While the flexibility is wonderful, it should be carefully managed to not lead to chaos.
The benefits of a single document atomicity with embedded objects is best illustrated with a shopping cart or an invoice. With relational databases, the storage of this information would require multiple tables with foreign keys, implying that data is split between all these tables when storing the data.

Then, when comes the time to display the information on screen or print the invoice, the information needs to be gathered again, using lengthy and CPU-intensive joins. Besides the performance impact of these joins, developers encounter difficulties known as impedance mismatch.
With a JSON, it make a lot of sense to gather all this information in a single atomic document, including all the information needed to produce the screen or invoice. Besides, only a single access to storage is required to get all this information, instead of one for each part of the join.
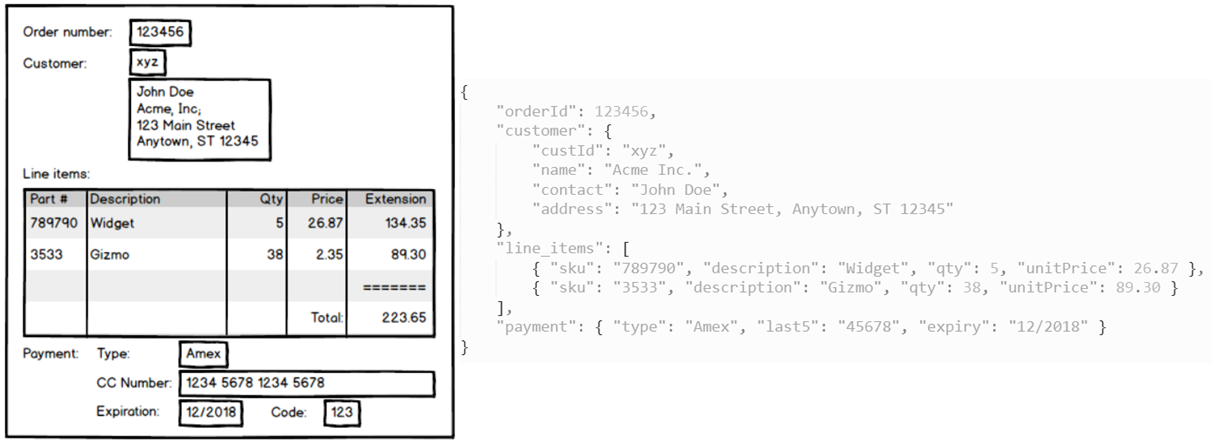
JSON Schema
JSON Schema is a vocabulary to annotate and validate JSON documents. It defines how a JSON should be structured, making it easy to ensure that a JSON is formatted correctly, and it is useful for automated testing and validating. In addition, JSON Schema provides clear human- and machine-readable documentation.
Schemas in general are used to validate files before use to prevent (or at least lower the risk of) software failing in unexpected ways. If there’s an error in the data being validated, the schema fails immediately. Schemas can serve as an extra quality filter for data.
Furthermore, when used in the context of the MongoDB validator, you can enforce the specified schema on insert and update operations in MongoDB for higher consistency and data quality.
JSON Schema is a standard providing a format for what JSON data is required for a given application and how to interact with it. Understanding JSON Schema involves a learning curve, so we suggest reading this guide for more information. But Hackolade makes is super simple for users as it dynamically generates JSON Schema for structures created with the tool. While a basic understanding of JSON Schema helps leverage the power of the tool, it is not necessary to know the JSON Schema syntax. Also, the tool onboards a validator so you can be sure that all quotes, braces, brackets, and commas are in the right places.
The design of a JSON document depend largely on its intended use within an application, so there’s no right or wrong way to design a document.. However, when an application a document, it is important to know exactly how that document should be organized. the application needs to know what fields are expected, and how the values are represented. That’s where JSON Schema comes in.
Note that JSON Schema itself is written in JSON. It is data itself, not a computer program. It’s just a declarative format for “describing the structure of other data”.
Hackolade Studio was built on top of JSON Schema, with extensions, and using it as an internal notation to represent all kinds of hierarchical structures, whether related to JSON or not. For a long time also, before the introduction of the Polyglot data modeling capability, JSON Schema was used also to convert models from one target technology to another. Hackolade supports the latest JSON Schema specifications :
- draft-04
- draft-06
- draft-07
- 2019-09
- 2020-12
Representation of nested structures in Entity Relationship Diagrams
The novel added-value provided by Hackolade Studio is its ability to represent nested structures inside an Entity-Relationship Diagram. In a way, we have bent and stretched the theory of ERDs to accommodate a user-friendly view of JSON document structures in ERDs.
If you use a traditional ERD tool to represent the above order document, it can only create a separate box for each nested object, something like this:
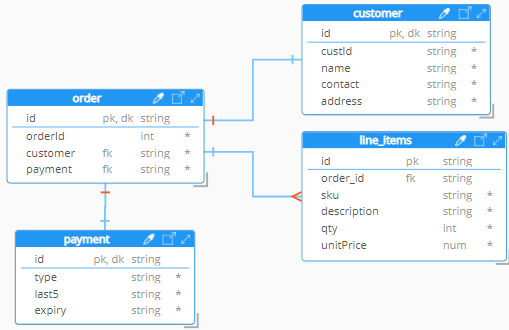
We think that this is a fundamentally flawed approach. One that is neither user-friendly nor scalable, particularly in the context of document databases with many different databases. We prefer to present the schema of the JSON in a single atomic unit which respects the structure, the sequence, and the indentation of the document:

We supplement this view with a hierarchical schema view which is sometimes preferred by users to manipulated nested objects:
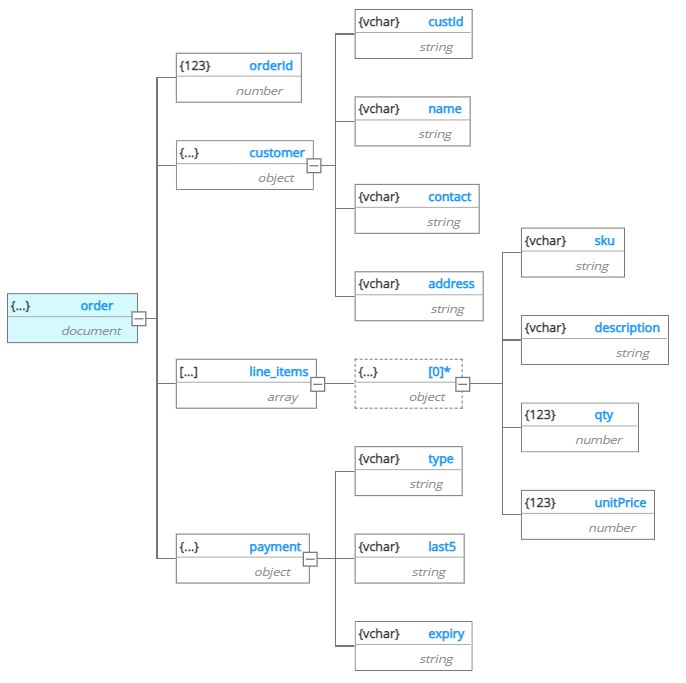
And finally, we facilitate the linking of multiple documents in an Entity-Relationship Diagram:

While foreign key relationships are not enforced by document databases, it is important for a better understanding, to document implicit relationships in the data.