
Parquet schema
Apache Parquet is a binary file format that stores data in a columnar fashion for compressed, efficient columnar data representation in the Hadoop ecosystem. Parquet files can be stored in any file system, not just HDFS. It is a file format with a name and a .parquet extension, which can be stored on AWS S3, Azure Blob Storage, or Google Cloud Storage for analytics processing.
Parquet file is an hdfs file that must include the metadata for the file. This allows splitting columns into multiple files, as well as having a single metadata file reference multiple parquet files. The metadata includes the schema for the data stored in the file.
Hackolade is a visual editor for Parquet schema for non-programmers. To perform data modeling for Parquet schema with Hackolade, you must first download the Parquet plugin.
Hackolade was specially adapted to support the schema design of Parquet schema. The application closely follows the Parquet terminology.
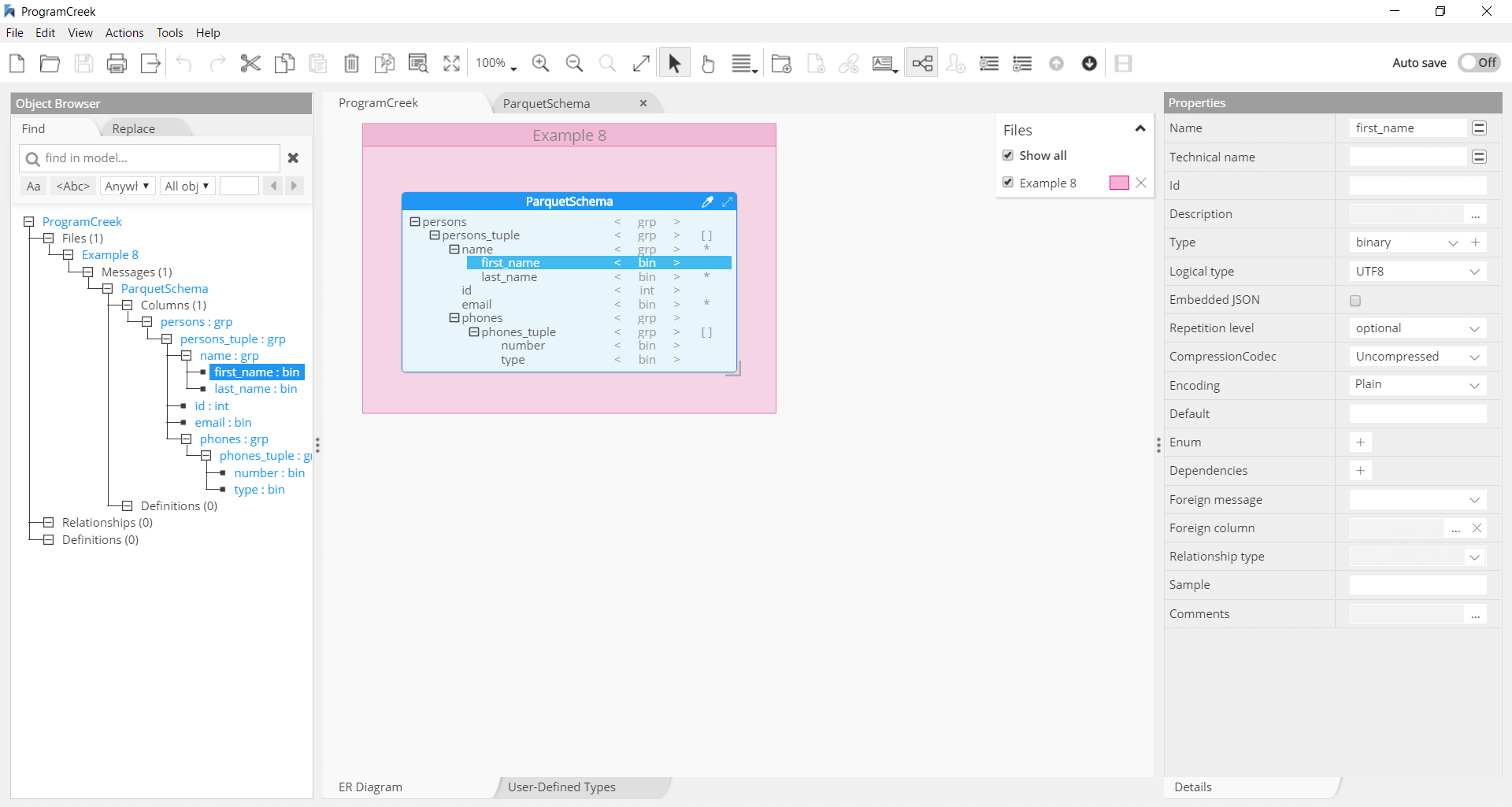
Parquet Schema
The root of the schema is a group of fields called a message. Each field has three attributes: a repetition, a type and a name. The type of a field is either a group or a primitive type (e.g., int, float, boolean, string) and the repetition can be one of the three following cases:
- required: exactly one occurrence
- optional: 0 or 1 occurrence
- repeated: 0 or more occurrences
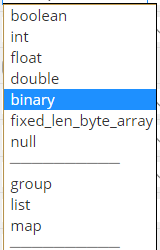
Data Types
The types supported by the file format are intended to be as minimal as possible, with a focus on how the types affect disk storage. This reduces the complexity of implementing readers and writers for the format. These types are intended to be used in combination with the encodings to control the on-disk storage format.
- BOOLEAN: 1 bit boolean
- INT32: 32 bit signed integer
- INT64: 64 bit signed integer
- INT96: 96 bit signed integer
- FLOAT: Single-precision (32-bit) IEEE 754 floating-point number
- DOUBLE: Double-precision (64-bit) IEEE 754 floating-point number
- BINARY: Sequence of 8-bit unsigned bytes
- BYTE_ARRAY: arbitrarily long byte arrays
- FIXED_LEN_BYTE_ARRAY: Fixed number of 8-bit unsigned bytes
Notice that there is no primitive string type. Instead, Parquet defines logical types that specify how primitive types should be interpreted, so there is a separation between the serialized representation (the primitive type) and the semantics that are specific to the application (the logical type). Strings are represented as binary primitives with a UTF8 annotation.
BYTE_ARRAY corresponds to binary in Parquet. Strings are encoded as variable-length binary with the UTF8 type annotation to indicate how to interpret the raw bytes back into a String. UTF8 is the only encoding supported in the format, but not every binary uses UTF8 because not all binary fields are storing string data.
Logical types are used to extend the types that parquet can be used to store, by specifying how the primitive types should be interpreted. This keeps the set of primitive types to a minimum and reuses parquet’s efficient encodings. For example, strings are stored as byte arrays (binary) with a UTF8 annotation. These annotations define how to further decode and interpret the data. Annotations are stored as a ConvertedType in the file metadata and are documented in LogicalTypes.md.
-
DATE is used to for a logical date type, without a time of day. It must annotate an int32 data types that stores the number of days from the Unix epoch, 1 January 1970.
-
TIME is used for a logical time type without a date with millisecond or microsecond precision. The type has two type parameters: UTC adjustment (true or false) and precision (MILLIS or MICROS, NANOS).
- TIME with precision MILLIS is used for millisecond precision. It must annotate an int32 that stores the number of milliseconds after midnight.
- TIME with precision MICROS is used for microsecond precision. It must annotate an int64 that stores the number of microseconds after midnight.
- TIME with precision NANOS is used for nanosecond precision. It must annotate an int64 that stores the number of nanoseconds after midnight.
-
TIMESTAMP is used for a logical type can be decoded into year, month, day, hour, minute, second and sub-second fields. It must annotate a single int64 number. The TIMESTAMP type has two type parameters:
- isAdjustedToUTC must be either true or false.
- precision must be one of MILLIS, MICROS or NANOS.
-
INTERVAL is used for an interval of time. It must annotate a fixed_len_byte_array of length 12.
-
JSON is used for an embedded JSON document. It must annotate a binary primitive type. The binary data is interpreted as a UTF-8 encoded character string of valid JSON. I’m tempted here to have an
-
BSON is used for an embedded BSON document. It must annotate a binary primitive type. The binary data is interpreted as an encoded BSON document. – pretty sure that it is not needed in a first phase??? Let’s see if customers ask for it.
-
LIST is used to annotate a group type that should be interpreted as lists.
-
MAP is used to annotate a group types that should be interpreted as a map from keys to values.
Forward-Engineering
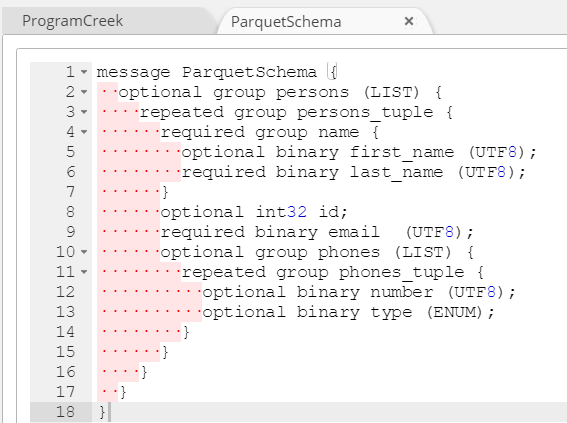
Hackolade dynamically generates Parquet schema for the structure created with the application.
The script can also be exported to the file system via the menu Tools > Forward-Engineering, or via the Command-Line Interface.
Reverse-Engineering
Hackolade easily imports the schema from .parquet files to represent the corresponding Entity Relationship Diagram and schema structure. You may also import and convert from JSON Schema and documents.
Cloud Object Storage
In the context of large-scale distributed systems like data lakes, data is often stored in object storage solutions like Amazon S3, Azure ADLS, or Google Cloud Storage. Parquet is designed to be a columnar storage format that allows for efficient processing and analysis of large datasets.
With Hackolade Studio, you can reverse-engineer Parquet files located on:
- Amazon S3
- Azure Blob Storage
- Azure Data Lake Storage (ADLS) Gen 1 and Gen 2
- Google Cloud Storage