
Synapse
Azure Synapse Analytics is a limitless analytics service that brings together enterprise data warehousing and Big Data analytics. It uses either serverless or provisioned resources with a unified experience to ingest, prepare, manage, and serve data for immediate BI and machine learning needs.
Azure Synapse and Parallel Data Warehouse are built on the SQL engine with standard ANSI-compliant T-SQL dialect of SQL language used on SQL Server and Azure SQL Database for data analysis.
JSON functions in Synapse enable users to combine NoSQL and relational concepts in the same database. Users can combine classic relational columns with columns that contain documents formatted as JSON text in the same table, parse and import JSON documents in relational structures, or format relational data to JSON text.
To perform data modeling for Synapse with Hackolade, you must first download the Synapse plugin. While similar to the SQL Server plugin, the Synapse plugin was specially adapted to support the data modeling of Synapse: adapted metadata properties, removed data types removed, adjusted index and constraints, plus adapted the generation of DDL Create Table syntax.
In particular, Hackolade has the unique ability to model complex semi-structured objects stored in columns of the (N)VARCHAR(MAX) and (N)VARCHAR(4000) data types. We're not talking about functions that "flatten" JSON into standard columns, which runs the risk of inconsistencies, if not errors, when doing the Cartesian product of multiple complex data types. But about the storage of entire JSON documents. The reverse-engineering function, if it detects JSON documents, will sample records and infer the schema to supplement the DDL table definitions.
The data model in the picture below results from the data modeling of the AdventureWorks sample database:
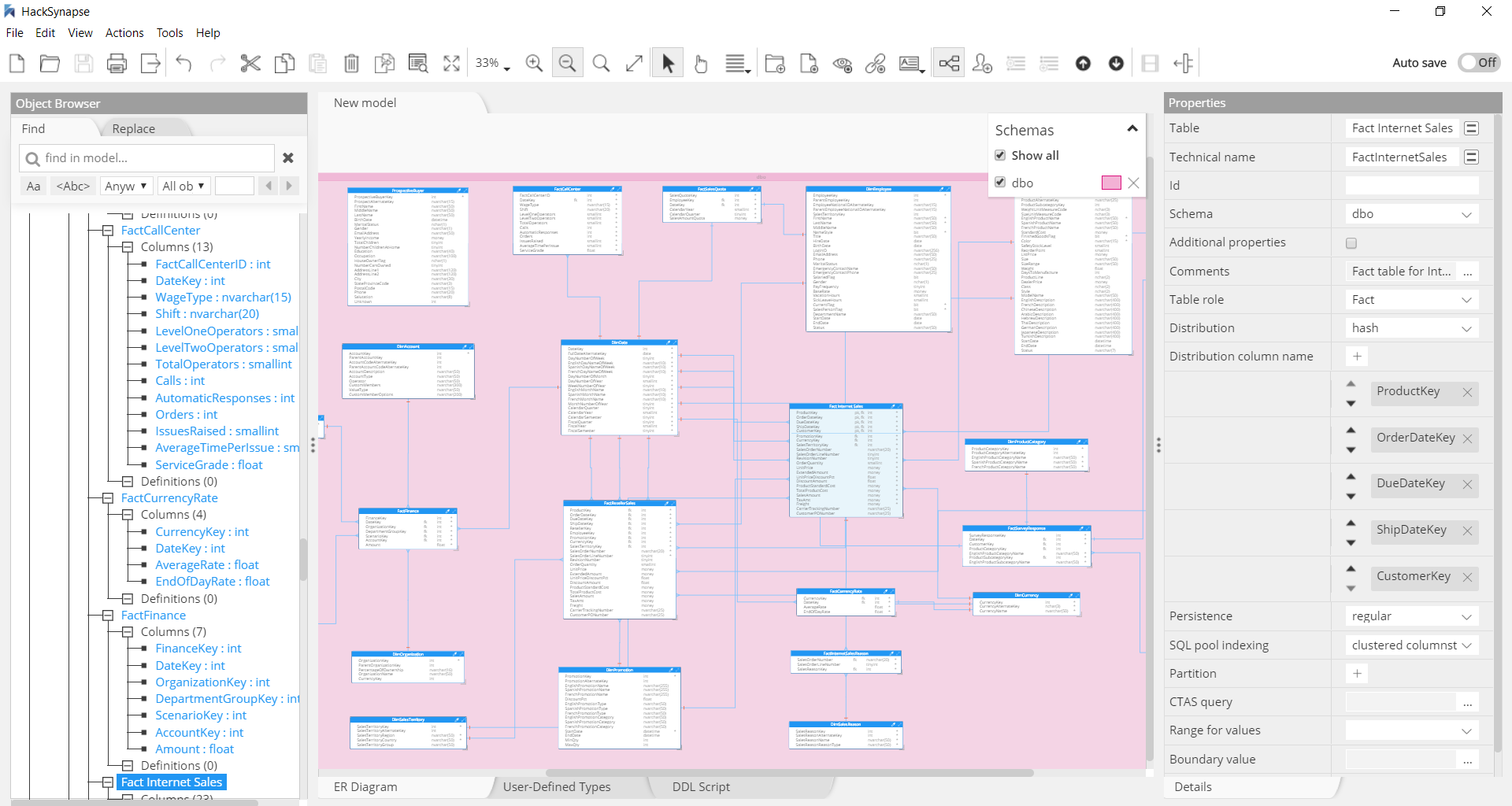
Schemas
Schemas are a good way to group tables, used in a similar fashion, together. If you're migrating multiple databases from an on-prem solution to SQL pool, it works best to migrate all of the fact, dimension, and integration tables to one schema in SQL pool.
Tables
All data in Synapse is stored in database tables, logically structured as collections of columns and rows, optionally with single-column or multi-column constraints. As users may name tables without the qualifier "fact" or "dim" in the table name, they may manually define a role for the table: Fact, Dimension, Outrigger (used to normalize data in dimension tables for snowflake schemas), or Staging. This table role does not get forward-engineered to the DDL Script.
A fundamental feature of SQL pool is the way it can store and operate on tables across distributions. SQL pool supports three methods for distributing data: round-robin (default), hash and replicated. While this might not always be true, and therefore can be adjusted by the user, the application will assign a role during reverse-engineering based on the following logic:
- hash distribution -> fact role
- replicated distribution -> dimension role
- round-robin distribution -> staging role
Constraints
PRIMARY KEY is only supported when NONCLUSTERED and NOT ENFORCED are both used. UNIQUE constraint is only supported with NOT ENFORCED is used. Check SQL pool Table Constraints. FOREIGN KEY constraint is not supported in Synapse SQL pool.
Unsupported table features
SQL pool supports many, but not all, of the table features offered by other databases. The following list shows some of the table features that aren't supported in SQL pool: Computed Columns, Indexed Views, Sequence, Sparse Columns, Surrogate Keys - Implement with Identity, Synonyms, Triggers, Unique Indexes, User-Defined Types. More info is available here.
Constraints in SQL Server are predefined rules and restrictions that are enforced in a single column or multiple columns, regarding the values allowed in the columns, to maintain the integrity, accuracy, and reliability of that column’s data. Constraints in SQL Server can be defined at the column level, where it is specified as part of the column definition and will be applied to that column only, or declared independently at the table level.
There are six main constraints that are commonly used in SQL Server: NOT NULL, UNIQUE, PRIMARY, FOREIGN, CHECK, and DEFAULT.
Data types
In Synapse, each column, local variable, expression, and parameter has a related data type. A data type is an attribute that specifies the type of data that the object can hold: integer data, character data, monetary data, date and time data, binary strings, and so on.
Additionally, in (N)VARCHAR(MAX) and (N)VARCHAR(4000) columns, Hackolade supports the data modeling of JSON files with standard JSON data types: string, number, object, array, boolean, and null.
Unsupported data types are 'geography','geometry','hierarchyid','image','text','ntext','sql_variant','xml' and useful alternatives are suggested here.
Views
Synapse supports standard and materialized views. Both are virtual tables created with SELECT expressions and presented to queries as logical tables. Views encapsulate the complexity of common data computation and add an abstraction layer to computation changes so there's no need to rewrite queries.
A standard view computes its data each time when the view is used. There's no data stored on disk. People typically use standard views as a tool that helps organize the logical objects and queries in a database. To use a standard view, a query needs to make direct reference to it.
A materialized view pre-computes, stores, and maintains its data in SQL pool just like a table. There's no recomputation needed each time when a materialized view is used. That's why queries that use all or subset of the data in materialized views can get faster performance. Even better, queries can use a materialized view without making direct reference to it, so there's no need to change application code.
Forward-Engineering
Hackolade dynamically generates the DDL script to create schemas, tables, columns and their data types, indexes and constraints for the structure created with the application.
The script can also be exported to the file system via the menu Tools > Forward-Engineering, or via the Command-Line Interface.
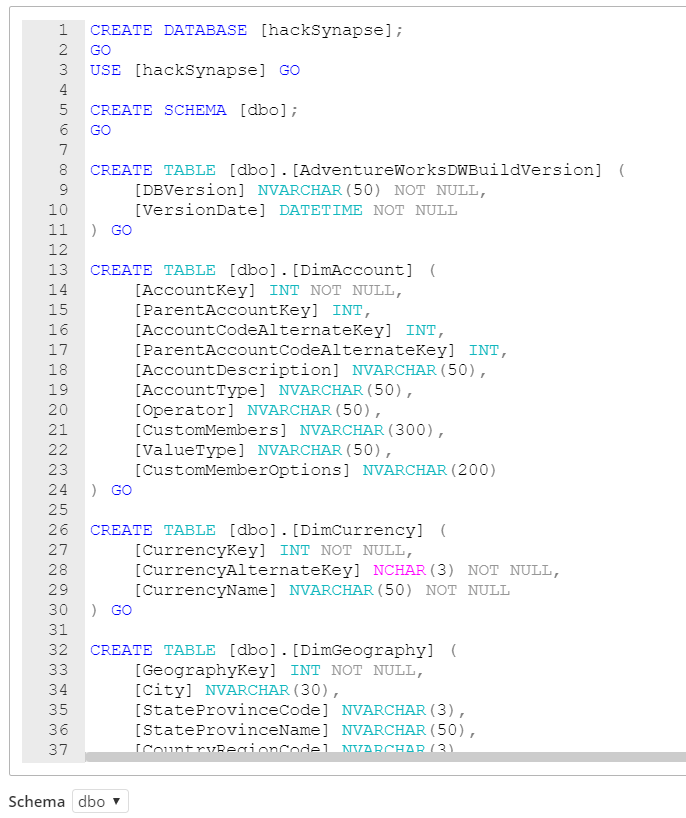
If you store JSON within (N)VARCHAR(MAX) or (N)VARCHAR(4000) columns, Hackolade allows for the schema design of those documents. However, the corresponding JSON structure is not forward-engineered in the DDL script, but is useful for developers, analysts and designers.
Reverse-Engineering
Details on how to connect Hackolade to a Synapse instance can be found on this page.
The Hackolade process for reverse-engineering of Synapse instances includes the execution of statements to discover schemas, tables, columns and their types, indexes and constraints. If JSON is detected in (N)VARCHAR columns, Hackolade performs statistical sampling of records followed by probabilistic inference of the JSON document schema.
For more information on Synapse in general, please consult the website and documentation.
During reverse-engineering, a "best guess" attempt is made to determine the table role (Fact vs Dimension vs Staging) using recommendations found https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-tables-overview#common-distribution-methods-for-tables, but admittedly, thes recommendations are ambiguous and it is likely that the user will need to adjust the role after reverse-engineering.